
NLP의 기초
최근 ChatGPT, Bard 등이 도입되며, 전세계적으로 NLP에 대한 관심도가 증가하였고 수요도 급격하게 증가하였다.
앞으로는 거대 언어 모델(LLM)과 Computer Vision을 융합하여 사용할 수 있는 인재의 수요가 높아질 것이라 예상되기 때문에 Computer Vision 외에도 NLP에 대해 학습하며, 실습도 하고자 한다.
NLP(Natural Language Processing, 자연어 처리)란?
컴퓨터가 인간의 언어(비정형 데이터, unstructured data)를 이해할 수 있도록 처리하는 기술이다.
컴퓨터는 2진 데이터(0과 1, binary data)로 되어 있는데 컴퓨터가 비정형 데이터를 이해하기 위해서는 2진으로 변환해줘야 한다.(encoding)

위 그림에서는 정형 데이터(structured data), 준정형 데이터(semi-structured data), 비정형 데이터(unstructured data)로 나누어진다. 빅데이터 붐이 확산된 것은 바로 비정형 데이터를 분석하면서부터 시작되었는데, 정형 데이터와 준정형 데이터는 구조가 어느정도 정해져 있어 분석이 상대적으로 쉽게 가능하지만 현실 데이터 중 20%정도 밖에 되지 않는다. 그런데 AI가 확산하면서 현실에서 생성되는 대다수의 비정형 데이터 분석이 가능해지면서부터 빅데이터 붐이 확산되게 되었다.
하지만 가장 NLP에 관심을 갖게 만든 가장 큰 영향을 미친 것은 단연코 OpenAI에서 개발한 ChatGPT라고 생각한다. 필자는 ChatGPT에 대한 포스팅(https://psleon.tistory.com/49)도 작성한 적이 있으니 관심이 있으면 참고하기 바란다.
NLP 활용 사례
컴퓨터가 인간의 언어를 이해할 수 있도록 처리하는 NLP를 산업군에서는 어떻게 활용하고 있을까?
NLP는 대부분 텍스트(text)로 많이 사용하는데, 텍스트 기반인 산업군에서는 NLP가 대부분 활용된다.
법률
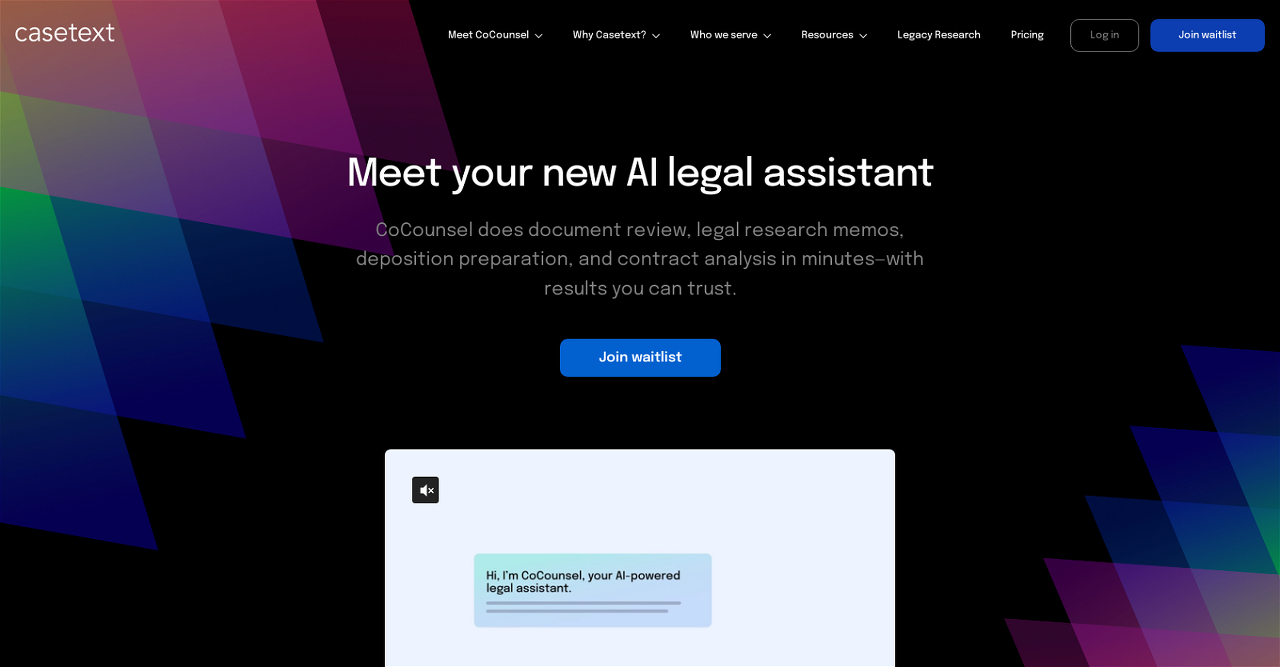
위 서비스는 AI를 도입해서 법률 처리를 하면서 판례나 서류를 읽고 위법 사항이 있는지 없는지 판단해주는 서비스인 casetext이다.
금융
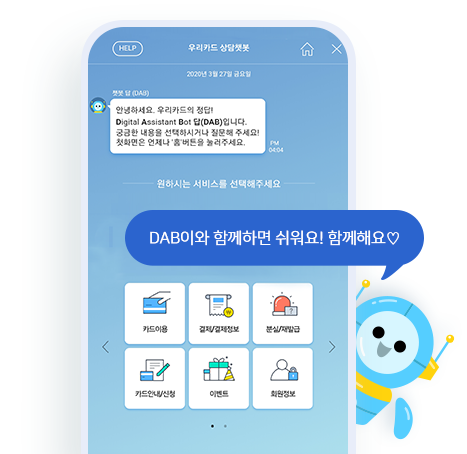
위는 우리카드 상담챗봇 이미지를 가져왔지만 우리은행뿐만 아니라 거의 모든 금융권 application에 챗봇이 사용된다.
마케팅
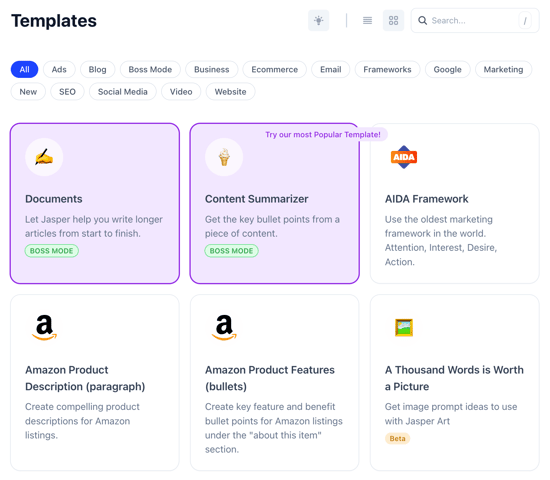
Jasper는 AI가 마케팅을 위한 글을 쓰는 등 마케터의 일을 도와주는 서비스이다.
필자가 소개한 활용사례 외에도 정말 무수히 많은 응용 사례가 있다.
NLP Task
NLP Task는 크게 자연어를 이해하는 NLU(Natural Language Understanding)와 자연어를 생성하는 NLG(Natural Language Generation) 2가지로 구분할 수 있다.

위 그림을 보면 NLP Task의 전체적인 흐름을 파악할 수 있다.
NLP로 어떠한 문제를 해결하기 위해서는 NLU에 해당하는지, NLG에 해당하는지 먼저 구분할 수 있어야 한다. 그 이후 벤치마크를 알아봐야 하는데, 벤치마크를 잘 알아보기 위해서는 메타(meta)가 만든 'Papers with code'(https://paperswithcode.com/)라는 사이트에 들어가서 데이터셋을 확인해보고 모델의 랭킹을 확인해보고 문제 해결을 시작하는 것을 추천한다.
자연어 이해(NLU, Natural Language Understanding)
자연어 이해에서 '이해'는 무엇을 이해한다는 것일까?
크게 두 가지로 나뉘는데, 첫째, 문법적으로 옳은 문장인가?에 관한 'syntactic'과 둘째, 문장의 의미를 이해하는가?에 관한 'semantic'이 있다. 즉, AI 모델이 문법을 잘 맞추고 문장이나 문서의 의미를 잘 알고 있다면 언어를 이해하고 있다는 것이다.
NLU Benchmarks

위 과제 외에도 '이탈 고객 예측, 상품 카테고리 분류, 위험 판별' 등의 문서분류(classification)와 '유사 문서 군집화, 유사 키워드 생성' 등의 군집화(clustering)도 있다.
자연어 생성(NLG, Natural Language Generation)
자연어 생성은 맥락/요청사항(prompt)을 이해하고 텍스트를 생성하는 것이다. 예를 들면, 기계 번역, 챗봇(질의응답), 요약, 컨텐츠 생성 등이 있다. 이 모든 것이 챗GPT가 하는 것이라고 생각하면 쉽다.
과거에는 특정 task마다 잘 수행하는 NLG 모델을 개발했으나 최근에는 GPT, LLaMA 하나의 크고 똑똑한 NLG 모델을 개발하는 식으로 패러다임이 전환되었다.
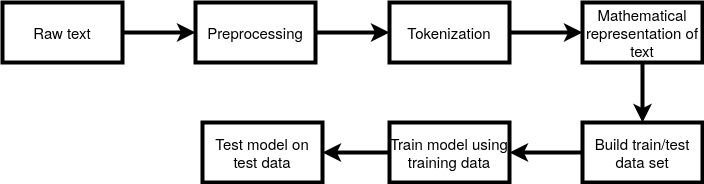
NLP Pipeline
NLP Pipeline은 아래와 같은데 역시 데이터가 가장 중요함을 확인할 수 있다.
NLP 기초 용어 정리
| 기술 or 모델 이름 | 설명 |
| One hot encoding(=representation) | categorical data를 one hot encoding으로 바꾸는 것 (정보의 손실이 큼, 옛날 방식) ex) "코딩하는 해커의 코딩 티스토리 블로그" 명사 사전: {코딩, 해커, 티스토리, 블로그} 인덱싱(indexing): {코딩: 0, 해커: 1, 티스토리: 2, 블로그: 3} 해커: [0, 1, 0, 0] / 티스토리: [0, 0, 1, 0] vector: 1 dimensional array |
| Bag-of-Word | 빈도 기반 단어 표현 ex) "코딩하는 해커의 코딩 티스토리 블로그" 명사 사전: {코딩, 해커, 티스토리, 블로그} 인덱싱(indexing): {코딩: 0, 해커: 1, 티스토리: 2, 블로그: 3} 빈도: {코딩: 2, 해커: 1, 티스토리: 1, 블로그: 1} BoW: [2, 1, 1, 1] |
| TF-IDF | 빈도 기반 단어 표현 (문서 기반) Term Frequency * Inverse Document Frequency * TF: 문서 N에서 특정 단어의 빈도수 * IDF: 특정 단어가 등장한 문서의 개수 idf(d, t) = log(n / 1+df(t)) * df: document frequency --------코딩--------해커--------티스토리--------블로그 문서 1---5-----------4-------------0-------------4-- 문서 2---0-----------2-------------8-------------2-- 문서 3---0-----------1-------------3-------------1-- ex: 코딩: 5 * log(3 / (1+1)) ex: 해커: 7 * log(3 / (1+3)) |
| Word2Vec | (dense) embedding - Neural Network Model (학습 가능) - 큰 dataset(a 1.6 billion words data set)으로 word embedding을 학습 - "의미" == similar words? - ("king" - "man" = queen") 학습 방법론 - Skipgram - CBOW - Glove - fastText |
| RNN | RNN: Recurrent Neural Network 시계열 데이터를 처리하기에 좋은 뉴럴 네트워크 구조 ex - 음성인식(speech recognition) - 음악 생성기(music generation) - DNA 염기서열 분석 - 번역기(machine translation) - 감정 분석(sentiment classification) |
| Transformer | Attention - RNN 계열(recurrent)의 단점인 long term dependency 해결 - 병렬 학습 가능 → fast Encoder + Decoder → Machine Translation Encoder → BERT 학습 방법론: Transfer learning(전이학습) Pre-training and Fine-tuning(사전학습과 파인튜닝) * fine-tuning: 미세하게 파라미터를 조정하는 것(task-specific, dataset) Decoder → GPT - LLM(Large Language Model) 발전 = General Model - Open-sourced Models(ex: LLaMA 2) - Closed API Models(ex: GPT-4) 학습 방법론: Few-shot learning - 인간이 학습하는 방식(few examples, instruction) |
| BERT | |
| GPT |
| 학습 방법론 | 설명 |
| feature extraction | 어떠한 text에서 feature들을 추출하는 것 |
| (feature) encoding | 어떠한 text에서 feature들을 추출하고 난 후 컴퓨터가 이해할 수 있는 2진수로 바꾸는 작업 |
| (word) embedding | (text → number) → model → topic == 'entertainment'? word2vec이 나오면서 가장 자주쓰는 용어, text를 number로 바꾼 그 number를 word embedding이라고 한다. 이외에도 'word representation, numerical representation, vectorization'이라고도 한다. 결국 모두 number를 의미하는 것이다. |
| word representation | |
| numerical representation | |
| vectorization | |
| statistical approach | 통계학적 접근 |
| neural network | 인공신경망 |
| NLP task | 설명 |
| language modeling | 언어 모델링 |
| document classification | 문서 분류 |
'NLP&LLM' 카테고리의 다른 글
| [LLM] 대형 언어 모델(LLM) 소개 (9) | 2024.10.27 |
|---|