
사이킷런을 활용해 훈련 세트와 테스트 세트로 나누기
훈련된 모델이 실전에서 얼마나 좋은 성능을 내는지 어떻게 확인할 수 있을까?
만약 훈련 데이터셋으로 학습된 모델을 똑같은 훈련 데이터셋으로 평가한다면 정확도 평가에 의미가 있을까?
이러한 주제에 대해 고민해보며 본 포스팅을 살펴보자.
모델의 성능 평가를 위한 훈련 세트와 테스트 세트
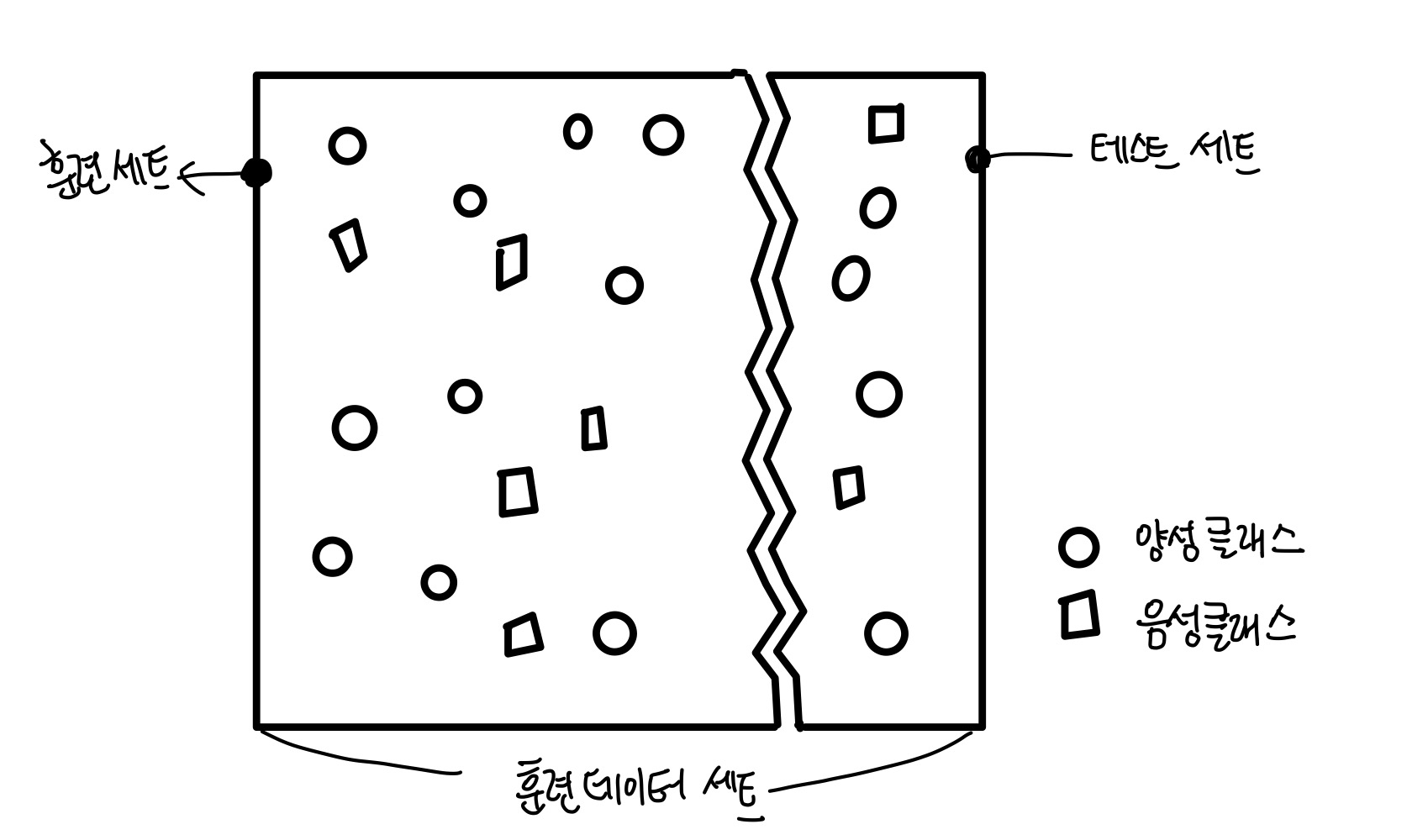
훈련된 모델의 실전 성능을 일반화 성능(generalization performance)라고 한다.
앞서 말한 것과 같이 훈련 데이터셋과 동일한 데이터셋으로 모델의 성능을 평가한다면 당연히 좋은 성능이 나올 것이다.
따라서 올바르게 모델의 성능을 측정하려면 위 그림과 같이 훈련 데이터셋을 두 덩어리로 나누어 하나는 훈련(training)에, 다른 하나는 테스트(test)에 사용하면 된다. 이때 각각의 덩어리를 training set와 test set라고 한다.
이렇게 나누고자 할 때에는 아래와 같이 2가지 규칙을 지켜야 한다.
훈련 데이터셋을 훈련 세트와 테스트 세트로 나누는 규칙
- 훈련 데이터셋을 나눌 때는 테스트 세트보다 훈련 세트가 더 많아야 한다.
- 훈련 데이터셋을 나누기 전에 양성, 음성 클래스가 훈련 세트나 테스트 세트의 어느 한쪽에 몰리지 않도록 골고루 섞어야 한다.
이러한 과정은 사이킷런에 준비되어 있는 도구를 사용하면 편하다. 지금부터 자세히 알아보자.
사이킷런의 train_test_split() 함수
sklearn.model_selection 모듈에서 train_test_split() 함수를 사용하면 쉽게 훈련 세트와 테스트 세트로 나눌 수 있다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.2, random_state=1234)
각 인자는 다음을 의미한다.
X : 독립 변수 데이터. (배열이나 데이터프레임)
y : 종속 변수 데이터. 레이블 데이터
test_size : 테스트용 데이터 개수를 지정한다. 1보다 작은 실수를 기재할 경우, 비율을 나타낸다.
train_size : 학습용 데이터의 개수를 지정한다. 1보다 작은 실수를 기재할 경우, 비율을 나타낸다. (만약, train_size가 0.8이면 test_size는 0.2가 된다.)
~ train_size와 test_size는 둘 중 하나만 기재해도 된다.
random_state : 난수 시드
'AI & BigData' 카테고리의 다른 글
| [AI] 과대적합(overfitting) / 과소적합(underfitting) (0) | 2023.07.25 |
|---|---|
| [AI] 테스트 세트로 모델을 튜닝하면 안되는 이유 (0) | 2023.07.25 |
| [AI] 로지스틱 손실 함수 - 크로스 엔트로피, 연쇄 법칙(Cross Entropy & Chain Rule) (3) | 2023.06.18 |
| [AI] YOLOv5를 활용한 히잡, 마스크 객체 인식 실습 (0) | 2023.06.03 |
| [AI] 당뇨병 환자의 1년 후 병의 진전된 정도를 예측하는 모델 만들기 - 1 (0) | 2023.05.26 |