
논문 리뷰: Explaining and Harnessing Adversairal Examples(FGSM)
- 논문 링크: https://arxiv.org/pdf/1412.6572
- 예제 코드(with PyTorch): https://github.com/PSLeon24/Paper-Implementation-with-PyTorch/blob/main/FGSM/FGSM.ipynb
- 세미나 자료
오늘은 적대적 공격, 적대적 예제를 공부할 때 가장 기반이 되는 논문인 "Explaining and Harnessing Adversarial Examples" 논문을 다루고자 한다.
이 논문은 2015년 ICLR에 출판된 논문이며, 논문의 저자는 생성형 적대적 신경망(Generative Adversarial Network: GAN)을 제안한 Ian J. Goodfellow이다.
1. Prerequisite
Adversarial Attack은 의도적으로 오분류를 이끌어내는 입력값인 Adversarial Examples를 만들어 내는 공격을 뜻한다.
Adversarial Examples는 모델 내에 perturbation이 삽입된 이미지를 뜻한다. 여기서 perturbation의 단어 뜻은 '섭동'이라는 것인데, 단어가 어려워 쉽게 노이즈(noise)라고 생각하면 된다. 적대적 예제에 대해서 이 논문에서는 이미지에 대해서만 한정하지만 사실 음성에 대해서나 텍스트 데이터에 대해서도 가능하다.

위 그림에서 x는 원본 이미지인 판다 이미지를 특정 모델이 57.7%의 confidence를 갖고 panda로 예측한 것이다. 하지만 여기에 0.007의 epsilon 만큼의 노이즈를 추가했더니 모델은 99.3%의 confidence를 갖고 gibbon(긴팔원숭이)로 잘못 예측하는데, 이때 노이즈가 포함된 판다 이미지가 바로 적대적 예제(adversarial examples)인 것이다. 우측에 노이즈가 포함된 판다 이미지의 경우 사람의 눈으로는 차이를 구별할 수 없다는 것이 특징이다. 수식의 경우는 나중에 자세히 설명하도록 하겠다.
이러한 적대적 공격은 왜 위험한 것일까?

2018년 CVPR에 출판된 "Robust Physical-World Attacks on Deep Learning Models" 논문에서는 위 그림과 같이 Stop 표지판에 적대적 스티커를 붙여 시속 45마일로 오분류하도록 만드는 방법을 발견했다. 이는 실제 자율주행 시스템에서 큰 문제를 야기할 수 있다. 자율주행 차량이 Stop 표지판을 보고 멈춰야하지만 오분류로 인해 정상적으로 주행하게 된다면 인명피해가 발생할 수 있기 때문이다. 이러한 사례 외에도 군사 목적의 AI 모델이나 스팸 방지 AI 모델에도 이러한 공격이 진행된다면 상당한 피해가 발생할 수 있다.
2. Background
과거 연구에서는 적대적 예제가 발생하는 원인에 대해서는 미스터리였으며, 여러 연구자들의 추측에 의하면 DNN(Deep Neural Network)의 극도의 비선형성 때문이라고 생각했고, 모델 앙상블의 부족과 지도 학습(Supervised Learning)에 있어서 불충분한 정규화의 결합 때문에 이러한 문제가 발생한다고 추측했다.
하지만 이 논문에서는 오히려 DNN의 비선형성이 문제가 아니라 고차원 공간에서의 선형성(Linear behavior)이 적대적 예제의 원인이 되기에 충분하다고 하였으며 이러한 관점을 통해 단순하고 빠르게 적대적 예제를 생성하는 방법을 설계하고 제안했다. 그 방법이 바로 적대적 예제를 공부하면 튜토리얼에 가장 자주 나오는 FGSM(Fast Gradient Signed Method)이다.
관련 연구로는 논문 저자 중 한명인 세게디(Szegedy)의 이전 연구인 'Intriguing Properties of Neural Networks" 에서 밝혀낸 다음과 같은 3가지가 이 논문과 관련된 내용이 포함되어 있음을 밝힌다.
- 적대적 예제는 원본과 너무 비슷해서 인간의 눈으로는 차이점을 구별할 수 없었다.
- 얕은 소프트맥스 회귀 모델(Shallow softmax regression models)들 또한 적대적 예제에 취약하다.
- 적대적 예제를 다시 모델 학습에 사용하는 적대적 훈련은 모델을 정규화하는 효과가 있다. 그러나 내부 계산에 있어서 비용이 많이 들기 때문에 실용적이지는 않다.
그리고 현대의 머신러닝 모델들을 기반으로 하는 분류기(classifier)가 테스트 데이터셋에 대해서는 높은 성능을 갖지만 본 논문에서 약간의 노이즈를 적용했을 때 높은 confidence를 갖고 오분류하는 결과를 보며 이러한 알고리즘들은 Potemkin Village를 건설했다고 표현한다.

Potemkin Village란 위 그림과 같이, 외관상으로는 좋아보이지만 사실은 빈껍데기와 같은 것을 뜻하는 용어이다. 즉, 모델이 실제 데이터를 이해하지 못하고 있지만 겉으로 보기에는 잘 작용하는 것처럼 보일 수 있다는 뜻이다.
3. Contribution
본 논문의 공헌은 아래의 3가지 정도로 생각할 수 있다.
첫째, 쉽고 빠르게 적대적 예제를 생성하는 방법인 FGSM(Fast Gradient Signed Method)를 제안했다.
둘째, 적대적 훈련(Adversarial Training)이 드롭아웃보다 더 효과적으로 정규화를 할 수 있음을 보였다.
셋째, L1 규제나 노이즈를 추가하는 것은 단순하지만 적대적 훈련보다 정규화 효과를 재현할 수 없었음을 실험을 통해 밝혔다.
4. Method
4.1. The Linear Explanation of Adversarial Examples
본 논문에서는 방법을 제안하기 전에 적대적 예제에 대해서 선형적 설명부터 진행한다. 일반적으로 이미지에 사용되는 RGB 채널의 경우 R, G, B 각각에 대해서 8비트 범위 내에 있는 256개의 값(0~255)으로 픽셀을 표현하기 때문에 매우 작은 색상의 변화에 대한 차이를 표현하는데 한계가 있다. 예를 들면, 시스템 상에서는 노이즈의 크기가 만약 0.3 픽셀 정도의 차이이고 기존의 값이 100이었다면, 100.3이 아닌 100으로 표현되는데 모델은 고차원 공간 상에서 이러한 미세한 차이가 축적된다면 큰 변화를 이끌어 낼 수 있다고 한다.


위 수식을 살펴보자. x˜ = x + η에서 x˜는 적대적 예제를 뜻하고 x는 원본 이미지, η(eta)는 아주 작은 perturbation을 뜻한다. 즉, 원본 이미지에 약간의 perturbation을 추가한 것이 adversarial example이라고 수식적으로 표현한 것이고 사실상 perturbation을 추가한 것은 모델이 같은 class로 판단하기 때문에 가중치 벡터인 w와 적대적 예제 x˜의 dot product를 하게 되면 아래와 같이 나타낼 수 있다.
wᵀ(x + η) = wᵀx + wᵀη (분배법칙)
이때, perturbation인 η의 infinity norm은 ε보다 작게 설정함으로써 아주 약간의 perturbation을 설정함으로써 사실상 원본을 거의 훼손하지 않으면서 모든 픽셀에 작은 변화를 줄 수 있다.
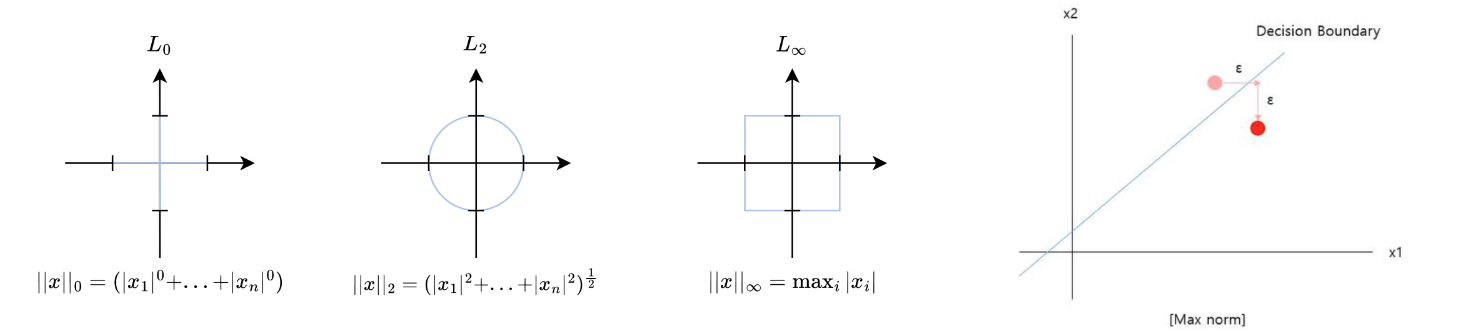
위 그림에서 infinity norm은 벡터의 모든 요소 중 가장 큰 값만을 고려하는데, 이를 통해 perturbation을 쉽게 계산할 수 있고, 모든 픽셀에 동일한 크기의 perturbation을 추가하기 때문에 전체 이미지에 걸쳐 변화가 균일하게 분산되는 효과가 있기 때문에 덜 눈에 띄는 효과가 있다. 그림의 우측은 이진 분류의 예시에서 원래 입력 데이터가 decision boundary를 넘을 만큼 perturbation을 적용하여 adversarial example을 생성하는 것을 시각화한 것이다.
4.2. Linear Perturbation of Non-Linear Models
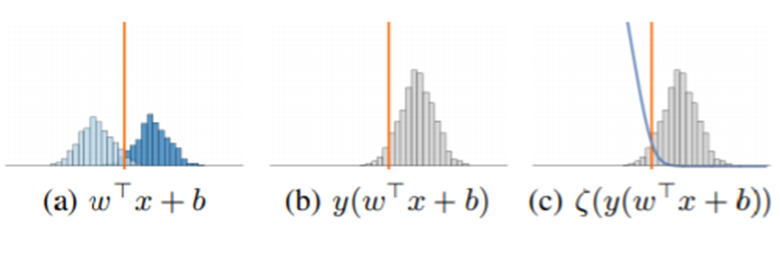
다음으로는 비선형 모델의 선형적 교란에 관한 내용이다. 많은 DNN 모델에서는 활성화 함수로 Sigmoid나 ReLU와 같은 비선형 함수를 사용한다.

하지만 이러한 활성화 함수들도 사실 특정 부분에서 선형적이라는 것을 알 수 있다. 먼저 saturating한 함수인 sigmoid와 non-saturating한 함수인 ReLU 모두 그림에서 빨갛게 처리한 부분에서는 선형적인 특징이 있다고 볼 수 있다.

따라서, 선형적인 특성이 있는 활성화 함수로 학습한 비선형적인 모델의 decision boundary 또한 선형적으로 나타나고 이러한 선형성으로 인해 4.1. The Linear Explaination of Adversarial Examples에서 제안한 적대적 예제가 비선형 모델에서도 충분히 발생할 수 있다고 한다.

위 그림은 이 논문에서 제안하는 FGSM의 핵심적인 수식이 포함된 그림이다.
perturbation인 η를 어떻게 만드는지에 관한 수식이고 지금부터 수식을 하나씩 뜯어서 살펴보자.
먼저, 노이즈의 크기가 너무 커지는 것을 방지하는 가중치인 ε과 sign() 함수를 곱하여 perturbation의 크기를 작게 맞춰준다는 것을 알 수 있다. 그리고 sign() 함수는 위 그림의 우측과 같이 부호를 반환하는 함수이다. 만약 입력이 0보다 작으면 -1을 0보다 크다면 1을 반환하는 함수이다. 그리고 ▽x는 gradient를 뜻하고 J() 함수는 cost function이다. 그리고 θ, x, y는 각각 모델의 파라미터, 인풋에 사용되는 이미지, y는 인풋 x에 대한 타겟이다. 즉, 수식을 전체적으로 이해해보자면, 모델 파라미터 θ를 갖는 모델에 x를 input으로 넣었을 때 실제 타겟인 y와의 loss를 계산하는 손실 함수의 gradient의 부호에 1을 곱한 값과 ε을 곱해서 perturbation을 만들어 이를 원본 입력에 추가함으로써 adversarial example을 만들 수 있다.

위 그림처럼 원본 이미지의 경우 loss가 최소가 되는 방향으로 학습을 진행하게 되지만, adversarial example의 경우 시각적으로는 동일하지만 잘못 분류하게 만들어 loss가 커지도록 한다. 또한 perturbation은 모델이 잘못 분류된 것에 대해 높은 confidence를 갖는 decision boundary로 이동하도록 설계되어 최종적으로 적대적 예제를 분류할 때 confidence도 증가하게 된다.

판다 예제를 통해 설명하자면 특정 decision boundary 안에 포함되어 정상적으로 분류하도록 만들어진 모델이 있는데, 판다 이미지에 perturbation을 추가하게 되면 시각적으로는 동일하지만 decision boundary를 벗어나서 잘못된 분류를 하게 된다.

위 그림은 조금 더 자세히 나타낸 예시이다.

그리고 본 논문에서는 ε을 점점 크게해보면서 MNIST와 CIFAR-10 데이터셋에 대해 실험을 진행했는데, ε이 커질수록 오분류율이 높아지는 결과를 확인할 수 있었다.

필자도 공개된 FGSM 소스코드를 활용하여 ε 변화에 따라 사전학습된 LeNet 모델의 Test Accuracy의 변화를 살펴봤다. 확실히 ε이 증가하면 할수록 Test Accuracy가 기하급수적으로 떨어지는 것을 확인할 수 있었다.

추가로 ε이 증가함에 따라 이미지가 어떻게 보이는지도 시각화 해봤는데 ε이 0.15일 때부터는 노이즈가 조금씩 눈에 보이는 것을 확인할 수 있었다.
5. Experiment
5.1. Adversarial Training of Linear Model Versus Weight Decay

Adversarial Training은 적대적 예제를 훈련 데이터로 사용하여 학습하는 것이다. 이 논문에서는 적대적 훈련을 가중치 감소와 비교하기 위해 로지스틱 회귀에서 발생하는 적대적 훈련을 예시로 든다. 이때 사용하는 Loss Function은 위와 같은데, 이때 ζ(zeta) 함수는 softplus function이다. softplus function은 활성화 함수 중 하나로 ReLU와 흡사하게 생긴 비선형 함수임을 알 수 있다. 잘못 구분된 것들에 대해서는 loss가 매우 높게 나오고 잘 구분된 것들은 loss가 0이 된다.
위 그림에서 (a)번째는 prediction 값을 나타내고, (b)는 GT(Ground Truth)에 y를 곱했기 때문에 제대로 예측했으면 양수, 틀리면 음수의 값을 갖게 된다. 그리고 softplus() 함수에 이 결과를 넣으면 틀린 결과에 대해서는 loss를 높게 주고, 맞은 결과에 대해서는 loss를 낮게 주게 만드는 것이다.
또한 이렇게 도출된 수식을 보면 L1 Regularization과 흡사한 형태를 갖고 있다는 것을 확인할 수 있다. 하지만 중요한 차이점이 있는데, L1 규제에서의 최적화는 일부 가중치를 0으로 만들고 다른 가중치는 상대적으로 크게 두는 경향이 있다. 즉, feature selection의 기능이 있어 input이 다차원일 때, 모든 차원에 대해서 조금씩 움직이는 것이 아니라, 몇 개의 차원에 대해 크게 움직인다. 하지만 softplus() 함수의 경우 포함될 수 있는 적대적 훈련 중에 모델은 모든 차원에서 가중치를 더 균일하게 조정하기 때문에 모든 차원에 대해서 조금씩 움직인다.
5.2. Adversarial Training of Deep Network

위 그림은 Adversarial Training에 대한 수식과 과정을 간단히 시각화한 것이다.
α는 Clean Data와 Adversarial Examples를 어떤 비율로 Training을 시킬지에 관한 가중치이다. 본 연구에서는 α를 0.5로 설정해서 5:5로 데이터를 훈련시켰다.
이렇게 Adversarial Training을 진행한 결과, 기존 모델의 경우 적대적 예제에 대해 89.4%의 error rate가 있었으나 적대적 훈련을 진행한 결과 error rate가 17.9%로 떨어진 것을 확인할 수 있었다. 물론 적대적 훈련을 진행해도 오분류 가능성이 여전히 존재했고 신뢰도도 81.4%로 매우 큰 값이었다.

위 그림은 MNIST 데이터셋에 대해 적대적 훈련을 거치지 않은 것과 적대적 훈련을 진행한 모델의 가중치를 시각화 한 것이다. 좌측의 Naively trained model을 보면 이미지 전반적으로 특징을 추출하는 것을 확인할 수 있다. 따라서 노이즈에 더 민감하다는 것을 확인할 수 있다. 반면, 우측의 적대적 훈련을 적용한 모델의 경우 특정 부분에만 집중함으로써 조금 더 localized 되어 있고 설명 가능한 형태로써 시각적인 특징을 갖게 됨을 확인할 수 있으며 따라서 적대적 공격에 조금 더 robust 하다고 볼 수 있다.
5.3. Different Kinds of Model Capacity
적대적 예제가 직관적이지 않은 이유는 우리가 인지할 수 있는 차원보다 훨씬 높은 고차원이기 때문이다.
또한 capacity가 낮은 모델은 여러 confident한 예측을 하지 못할 것이라고 하지만 이는 정확하지 않다.
아래 수식은 매우 non-linear한 모델인 shallow RBF network의 수식이고, 이를 예를 들어 살펴보자.

RBF network 자체는 적대적 예제에 면역을 갖고 있어 error rate는 55.4%로 다른 모델보다 낮은 에러율을 보인다는 것을 알 수 있다. 그리고 주목할 점은 오분류한 example에 대한 confidence가 1.2%로 매우 낮다는 것인데, 이는 모델이 완벽하게 이해하지 못한 데이터에 대해서는 confidence를 대폭 낮춘 것이다. 하지만 RBF network의 경우 테스트 정확도가 60.6%로 낮기 때문에 실용성은 떨어지고, 이 아이디어에 영감을 받아 deep RBF network를 포함한 다양한 모델을 탐색하고자 했으나 어려운 작업이라고 한다.
5.4. Why do Adversarial Examples Generalize?
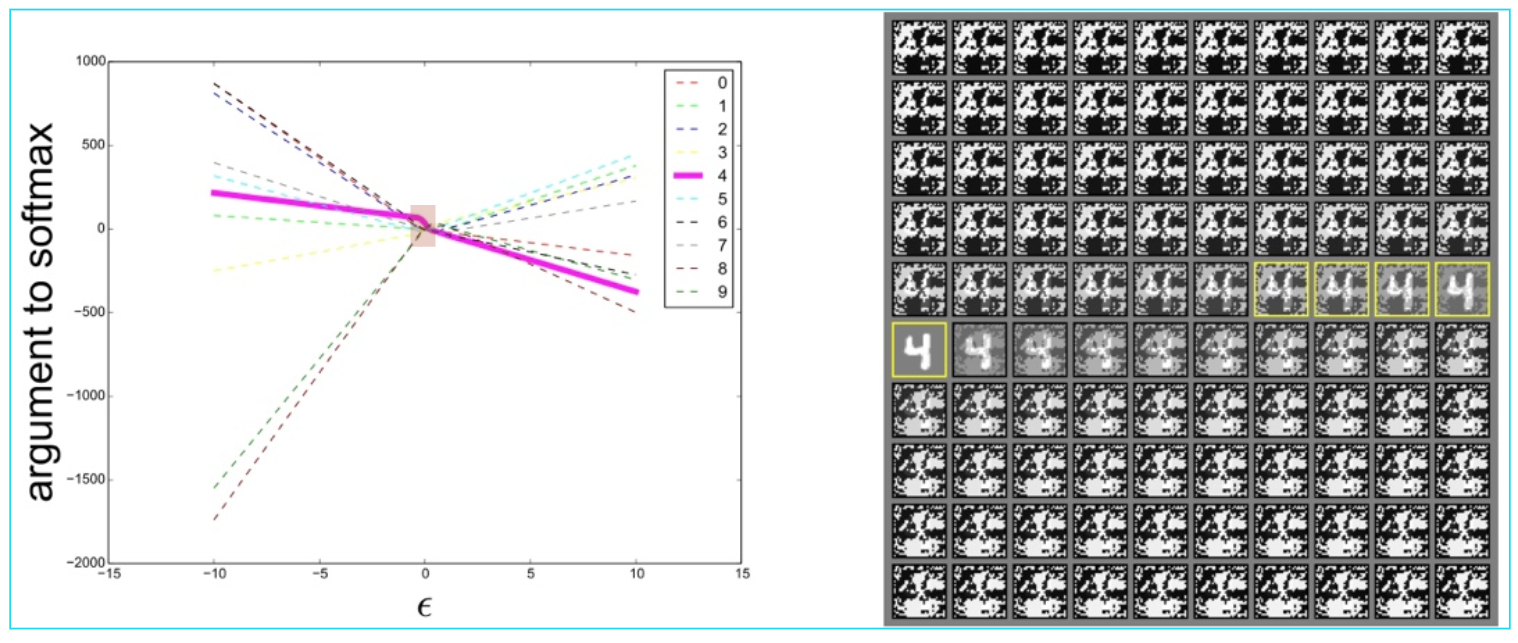
적대적 예제로 인해 특정 모델에서 오분류가 일어난다면 다른 모든 구조의 모델에서도 동일한 오분류가 발생한다. 이런 성질을 transferability 하다고 한다. 선형적인 관점에서 적대적 예제는 높은 차원에서 발생하는데 앞에서 확인했듯이 가장 중요한 것이 바로 ε 값이다. 아래 그림은 ε의 크기에 따라서 augmented softmax가 변하는 것을 보여주는데 4를 올바로 분류하고 싶을 때, 가운데 빨간 부분(ε이 -1 ~ 0 사이)이 4에 대한 softmax가 가장 큰 것을 확인할 수 있고 그 외에 부분은 4에 대한 softmax가 가장 크지 않다는 것을 알 수 있다. 그리고 ε의 크기에 따라서 softmax가 linear한 형태로 이루어져 있다. 그리고 대부분의 model architecture가 아래와 같이 linear한 형태로 이루어져 있기 때문에 모델을 훈련할 때 대부분 비슷한 weight를 갖게 되기 때문에 적대적 예제는 일반화된다고 할 수 있다.
5.5. Alternative Hypothesis
가설 1. 모델이 '실제'와 '가짜' 데이터를 구별하는 방법을 생성적 훈련(generative training)을 통해 '실제' 데이터에 대해서만 confidence를 갖는다.
- MNIST에 대해서 error rate가 0.88%인 MP-DBM 모델을 통해 진행하였으나, ε이 0.25인 경우 97.5%의 높은 error rate를 얻었다. 따라서 이 가설은 옳지 않다.
가설 2. 여러 모델들의 가중치를 평균내면 적대적 예제가 사라질 수 있다.
- 12개의 MNIST maxout network들을 앙상블해서 훈련시켰음에도 ε이 0.25인 경우 91.1%의 error rate를 얻었다. 따라서 이 가설은 옳지 않다.
6. Conclusion
- 적대적 예제는 머신러닝에서 널리 퍼진 현상으로, 모델의 과적합 때문에 발생하는 것이 아닌 고차원 공간에서 모델의 선형성 때문에 발생한다.
- 이러한 적대적 예제는 신경망의 근본적인 특성을 강조한다. 즉, 인간이 감지할 수 없는 작고 의도적인 교란에 쉽게 속을 수 있다는 것이다.
- 이 연구에서는 적대적 예제를 효율적으로 생성하고 적대적 훈련에 사용할 수 있는 Fast Gradient Sign Method(FGSM)을 제안했다.
- 적대적 훈련은 모델을 robust하게 하고 적대적 공격으로부터 더 유연하게 대처할 수 있도록 한다.
* 코드를 돌려보고 궁금한 점
- adversarial example을 캡쳐해서 다시 사용하면 noise가 그대로 유지될까?
'Paper' 카테고리의 다른 글
| [Paper Review] Denoising Diffusion Probabilistic Models (2) | 2024.12.02 |
|---|---|
| [Paper Review] Disrupting Deepfakes: Adversarial Attacks ~ (9) | 2024.10.01 |
| Face Identification, Recognition, Verification 오픈소스 정리 (0) | 2023.08.24 |
| [Paper] Face Recognition 관련 논문 정리 (0) | 2023.08.24 |