
논문 리뷰: Disrupting Deepfakes: Adversarial Attacks on Conditional Image Translation Networks
- 논문 링크: https://arxiv.org/pdf/2003.01279
- 깃허브 링크: https://github.com/natanielruiz/disrupting-deepfakes?tab=readme-ov-file
Background
오늘은 2020년 CVPR 워크샵에서 발표된 논문인 "Disrupting Deepfakes: Adversarial Attacks on Conditional Image Translation Networks"이라는 논문에 대해 리뷰하고자 한다. 최근 Adversarial Attack에 관심을 갖게 되고난 후 "딥페이크 범죄"가 사회적 이슈가 되었다. 그리고 필자는 사람 눈에는 안보이지만 아주 미세한 노이즈를 사진에 넣어서 GAN이나 Diffusion 모델로 딥페이크를 하게 됐을 때 이를 못하도록 막는 기술을 연구하고 싶다는 생각을 했고, 관련 연구들을 서베이하던 중 필자의 방향과 가장 비슷한 논문 2개 정도를 발견했고, 오늘 그 중 하나를 리뷰하고자 한다.
원본 이미지에 아주 미세한 노이즈를 적용한 후 딥페이크를 진행했을 때의 결과 이미지는 아래와 같다.

위 결과를 보면 알 수 있듯이, 노이즈 없이 원본 이미지에 딥페이크를 진행하면 성공적으로 얼굴이 변경되지만, 약간의 노이즈를 삽입한 이미지를 보면, 사람 눈에는 전혀 보이지도 않지만 딥페이크를 진행하면, 완전 사람이 알아볼 수 없는 형태인 블러링된 상태로 출력된다는 것을 확인할 수 있다. 여러 딥페이크 범죄 관련 예방을 위해 진행된 연구들은 대다수 딥페이크 탐지기에 대한 연구인데, 이는 범죄가 발생하기 전에는 전혀 예방할 수 없다는 한계가 있지만, 이 연구는 본질적인 문제인 사전 예방이 가능한 방법을 제안했다는 점에서 contribution이 있다고 할 수 있다.
본 논문 리뷰는 Introduction, Contribution, Method, Experiment, Conclusion 순서로 작성하고자 한다.
Abstract
딥러닝을 사용한 얼굴 수정 시스템은 점차 강력해지고 접근이 쉬워졌다. 사람의 얼굴 사진이 주어지면 이러한 시스템은 완전히 같은 사람의 얼굴을 다른 표정이나 자세의 새로운 이미지로 만들어낼 수 있다. 또한 몇몇 시스템은 머리 색깔이나 나이와 같이 특정 속성에 대해서 수정할 수 있다. 이렇게 수정된 이미지나 비디오를 딥페이크(Deepfakes)라고 부른다. 제약없이 사람을 수정한 이미지를 만드는 악성 사용자로부터 예방하기 위해서 우리는 이미지 변환 시스템의 결과 이미지를 방해하는 적대적 공격을 생성함으로써 이 새로운 문제를 해결하고자 한다. 우리는 이 문제를 딥페이크 방해(disrupting deepfakes)라고 한다. 대부분의 이미지 변환 모델의 아키텍처는 속성에 따라 조건화(e.g., 사람의 얼굴을 웃게해줘)된 생성 모델들(generative models)이다. 우리는 먼저, 다양한 클래스로 일반화되는 클래스 이전 가능한 적대적 공격을 최초로 제안하고 성공적으로 적용했다. 이로 인해, 공격자는 조건화 클래스에 대한 지식이 필요하지 않다. 다음으로, 우리는 강인한 이미지 변환 신경망으로 한걸음 나아가기 위해 생성형 적대적 신경망(GAN)을 위한 적대적 학습(adversarial training)을 최초로 제안하고 이 또한, 성공적으로 적용했다. 마지막으로, 그레이박스 시나리오에서 블러링은 방해에 대한 성공적인 방어를 구축할 수 있다. 우리는 블러 방어를 피하기 위한 확산 스펙트럼의 적대적 공격(spread-spectrum adversarial attack)을 제안한다.
1. Introduction



생성형 적대적 신경망(GAN: Generative Adversarial Network)와 노이즈 제거 확률 확산 모델(DDPM: Denosing Diffusion Probabilistic Models)가 등장함에 따라 원본 이미지를 조작하여 새로운 얼굴로 만들거나 혹은 성별을 바꾸거나 헤어 스타일을 바꾸는 등 다양하게 특정 속성들을 변경할 수 있게 되었다.
이와 같이 딥페이크 기술이 널리 퍼지고, 일반인들도 GitHub에 공개된 오픈소스를 통해 쉽게 사용할 수 있도록 되자, 악성 사용자(malicious actors)들은 원본 이미지의 대상의 허락없이도 함부로 딥페이크 기술을 사용하여 가짜 뉴스를 만들거나 혹은 최근 이슈가 되고 있는 성범죄 등 다양한 사회적 문제를 일으키고 있다.

이러한 딥페이크 범죄의 대상은 직업, 나이, 성별에 관계없이 피해가 확산되고 있다. 가장 큰 문제는 피해가 발생한 후 이를 발견할 수 있고 딱히 예방 방법이 없다는 것이다.
이러한 딥페이크 범죄를 막기 위한 여러 연구가 존재했는데, 그 중 대표적인 분야가 바로 'Deepfake Detection'이다.

실제, 언론이나 구글 스칼라를 통해 확인해보면 deepfake detection과 관련된 여러 내용이 나온다. 이는 딥페이크 기술을 사용해 조작된 fake 이미지 혹은 영상인지 아니면 real 이미지 혹은 영상인지 감지하여 판별하는 시스템이다. 이는 가짜 뉴스 판별에는 도움이 되지만 현재 이슈가 되고 있는 딥페이크 성범죄에 대해서는 큰 실효성이 없다. 그 이유는 성범죄는 예방이 최우선 목적이 되어야하며, 이미 범죄가 발생한 후에는 피해자에게 큰 정신적 고통을 줄 수 있는 큰 문제이기 때문이다. 따라서, 애초에 딥페이크를 통해 얼굴을 조작하는 등의 기술을 원천적으로 차단하고 예방할 수 있어야 한다.
본 논문에서는 'Deepfake Disruption'이라는 새로운 분야를 제안한다. 즉, 원본 이미지에 사람 눈으로는 거의 식별이 불가능한 미세한 노이즈를 삽입하여 적대적 예제(adversarial example)를 만든다. 그리고 해당 적대적 예제를 통해 얼굴 조작(face manipulation)을 진행하면 이미지가 블러링되거나 파괴된 이미지가 출력되는 방법이다. 물론 이 연구에서는 GAN 모델에 대해서만 진행했기 때문에 약간의 아쉬움이 남는다. 차후 내 연구에서는 Diffusion 모델에도 강건하게 공격할 수 있는 Method를 제안하고 싶다.
필자는 최근 딥페이크 범죄가 이슈화되기 전부터 내가 공부하는 Adversarial Attack이라는 분야를 활용하여 딥페이크를 막을 수 있는 기술을 만들고 싶었는데, 본 논문은 정확하게 내가 원하는 내용과 일치하는 논문이다. 이 논문에서 원본 이미지에 미세한 노이즈를 삽입하여 Adversarial example을 만드는 내용은 2015년 ICLR에 발표된 Ian. J. Goodfellow의 논문인 "Explaining and Harnessing Adversarial Examples"를 보면 더 자세히 이해할 수 있다. 본 논문은 필자가 리뷰한 적이 있는 논문으로, 아래 링크를 통해 학습할 할 수 있다.

위 그림은 Adversarial Attack을 한번에 정리하여 나타낸 그림이다. 어떤 모델이 있고, 그 모델은 그림의 좌측과 같이 판다 이미지에 대해서 57.7%의 confidence를 갖고 판다로 예측하는 모델에 아주 미세한 노이즈(0.007 만큼 곱한 아주 작은 노이즈)를 원본 이미지에 삽입하면 그림의 중앙에 위치하는 적대적 예제(adversarial example)가 만들어지고, 이는 모델이 99.3%의 confidence를 갖고 긴팔원숭이(gibbon)이라고 오분류(misclassify)를 이끌어낸다. 이렇게 오분류를 이끌어내는 task를 적대적 공격(adversarial attack)이라고 한다.
Explaining and Harnessing Adversarial Examples 논문의 저자 중 한명인 세게디가 L-BFGS라는 방법을 제안한 이후, FGSM이 등장하고 그 이후 더 강력한 공격인 C&W Attack, PGD, Auto Attack 등 다양한 공격 기법이 등장했다.

이러한 적대적 공격의 원리는 L-Norm을 활용하여 정해진 ε보다 작은 노이즈를 생성하여 적대적 예제를 만들고 이렇게 만들어진 적대적 예제는 결정 경계(decision boundary)의 범위 밖에 위치하게 되어 오분류를 이끌어 내는 것이다.

Adversarial Attack에는 크게 다음과 같은 2가지 공격이 존재한다.
- White-Box Attack: 공격자가 사전에 모델의 종류나 파라미터와 같은 모든 정보에 접근할 수 있을 때 진행되는 적대적 공격
- Black-Box Attack: 공격자가 사전에 모델과 관련된 정보를 모르지만 대표적인 모델에 대해서 공격을 진행 후 adversarial example의 전이성(transferability)을 활용한 공격
본 논문에서는 다음과 같이 위 두 가지의 공격 시나리오를 적절히 조합한 'Gray-Box Scenario'를 정의하고 이 환경에서의 공격을 제안한다.

그레이박스 시나리오는 모델과 모델의 파라미터에 대해서는 완벽히 알고 있지만 방어를 위한 전처리 과정(예를 들면 블러링)에 대해서는 무시하는 것이다.

위 그림은 본 논문의 deepfake disruption 과정을 나타낸 그림이다. 원본 이미지와 적대적 예제에 대해서 각각 StarGAN을 활용한 face manipulation을 진행했을 때, 어떤 결과가 나오는지 한눈에 보여준다. 먼저, 원본 이미지로 딥페이크를 진행하면 얼굴은 동일한데 헤어 색상이 변한 것을 확인할 수 있다. 하지만 공격이 진행된 이미지에 대해서 딥페이크를 진행하면 알아볼 수 없는 이미지로 결과가 출력된다. 즉, 필자가 앞서 말한 것과 같이 딥페이크에 대해 예방할 수 있는 방법이다.
예시를 조금 더 살펴보자.

StarGAN이나 GANimation을 통해 노이즈 없이 정상적인 이미지로 딥페이크를 진행했을 때는 그림의 Original Output과 같이 정상적으로 딥페이크 결과물이 생성되는 것을 확인할 수 있다.

그런데 Disruption(일종의 noise)를 원본 이미지에 삽입하면, 사람 눈으로 보기에는 원본 이미지와 동일하지만 딥페이크를 진행한 결과물을 보면 거의 사람의 형체를 알아볼 수 없는 결과물이 생성되는 것을 확인할 수 있다.
2. Contribution
본 논문의 공헌은 크게 4가지로 정리할 수 있다.
- 이미지 변환 모델에 적대적 공격 방법들을 적용함으로써 딥페이크를 방해하기 위한 베이스라인을 제안했다.
- 조건부 이미지 변환 모델들의 disruption을 다루고, 하나의 조건화된 클래스로부터 다른 클래스로 전이되는 새로운 방해 방법을 제안하고 평가했다.
- 최초로 생성형 적대적 네트워크를 위한 적대적 훈련을 제안하고 평가했다.
- 그레이박스 시나리오에서 블러 방어를 회피할 수 있는 새로운 확산 스펙트럼 방해를 제안했다.
3. Method
Method 파트는 이미지 변환 방해 그리고 조건부 이미지 변환 방해, 다음으로 GAN 적대적 훈련, 마지막으로 블러 방어의 확산 스펙트럼 회피와 같이 총 4가지의 하위 섹션으로 구성된다.
3.1. 이미지 변환 방해
적대적 예제를 만드는 이전 연구들과 마찬가지로 이 연구에서는 disruption을 만들기 위해 아래와 같이 사람 눈으로는 식별할 수 없는 작은 노이즈(perturbation) η를 원본 이미지 x에 삽입하여 disrupted image x~(x tilda)를 생성한다. 수식으로는 다음과 같다.

이때, 노이즈 η를 만들기 위해 본 논문에서는 이전의 연구들 중 FGSM과 I-FGSM을 사용했다.

FGSM은 첫번째 수식과 같이 모델의 손실 함수 L에 대한 그레이디언트를 구하고 그 그레이디언트의 부호에 1을 곱한 값을 ε만큼 곱하여 노이즈를 생성한다.
I-FGSM에서 I는 Iterable을 뜻하고, FGSM을 α-step만큼 반복하여 원본 이미지에 노이즈를 점진적으로 추가하여 더 강력한 적대적 예제를 생성한다. 단, ε의 범위를 벗어나면 클리핑하도록 하여 제약 조건 범위 안에서의 최대 크기의 노이즈를 생성하도록 한다.
G를 이미지 변환을 위한 GAN의 생성자라고 하고 y와 y~를 각각 x와 x~를 통해 만들어진 변환된 결과 이미지라고 하면 수식으로는 다음과 나타낼 수 있다.

이 논문에서는 위 수식에서 네모 박스 표시한 수식과 같이 눈에 띄는 손상이 발생하여 사람이 봤을 때 이미지가 변경되었다는 것을 알아차리고 이미지에 대해 불신하게 될 때 공격이 성공적이라고 간주한다.
또한, 이전의 적대적 공격에 대한 연구에서는 L0, L2 그리고 L-infinity distance metrics을 사용하여 최대한 적은 왜곡을 보이는 공격에 초점을 맞췄지만 본 논문에서는 참조 이미지 r에 대해 출력 왜곡을 최대화하여 잘못된 이미지를 만드는 것을 목표로 한다. 이를 위한 수식은 다음과 같다.

위 수식을 살펴보면, 2가지 케이스로 나뉘어 수식을 정의했다. 이때, r은 ground-truth 역할을 하는 정상적으로 잘 변환된 이미지로 r = G(x)이다.
첫 번째 수식부터 확인해보면, 적대적 예제인 G(x + η)와 r 간의 손실함수 값이 최대가 되는 η를 찾는 것이다. 단, 이때 L-infinity norm을 적용하여 ε보다 작은 최대 크기의 η를 찾도록 한다.
다음으로, 두 번째 수식은 targeted disruption에 관한 수식으로, r이 첫 번째 수식과 같이 정상적으로 만들어진 이미지일 수도 있으나 이미 잘못된 결과를 만들어 두고 이와 같은 결과를 유도할 수도 있는데 이에 관한 수식이다. 이 수식 또한 L-infinity norm을 적용하여 ε보다 작은 최대 크기의 η를 찾는데, 첫 번째 수식과는 반대로 적대적 예제인 G(x + η)와 r 간의 손실함수 값이 최소가 되는 η를 생성하여 최대한 이미 왜곡이 심하게 진행되어 있는 참조 이미지 r과 최대한 흡사한 결과가 출력될 수 있는 노이즈를 찾는 것이다.
3.2. 조건부 이미지 변환 방해

본 논문에서는 많은 이미지 변환 시스템의 경우 입력 이미지뿐만 아니라 대상 클래스에 대해서도 조건화과 된다고 하며, y = G(x, c)와 같이 나타낼 수 있다고 한다. 이때 x는 입력 이미지이고, c는 대상 클래스, y는 출력 이미지를 뜻한다고 한다.
대상 클래스에 대해서는 예시로 쉽게 설명해뒀는데, '금발', '갈색 머리'와 같은 데이터셋의 속성이 될 수 있다고 한다.
즉, 어떤 이미지가 주어졌을 때, 성별을 변환하거나 표정을 변환하는 방법들을 통틀어서 조건부 이미지 변환(conditional image translation)이라고 하고 본 논문에서는 이에 대한 방해 방법을 다음과 같이 제안했다.

내용을 보면 특정한 조건에 대해서만 방해가 되는 것이 아닌 여러 클래스에 대해 동일하게 보장되는 즉, 클래스 전이 가능한 방해를 찾기 위한 수식을 제안함을 확인할 수 있다. 그 이유는 일반적인 적대적 공격을 진행하면 특정 클래스에 대해서만 방해 효과를 갖게 되는데, 특정 얼굴 표정의 변화와 같은 특정 조건이 아닌 다양한 일반적인 조건에 대해서도 공격이 가능해야 실제 딥페이크 예방에 효과적이기 때문이다.
그래서 수식 (7)을 보면 클래스 전이 가능한 방해에 대해 기댓값 표현인 E를 표현해서 나타낸 것을 확인할 수 있다. 이전과 마찬가지로 L-infinity norm을 적용하여 η가 ε보다 커지지 않도록 제약 조건을 두고, G(x + η, c)와 r 사이의 손실 함수의 결과의 평균이 최소화 되는 η를 찾아 다양한 조건 c(e.g., 얼굴 표정, 성별, 나이)에 대해서 변환을 잘 망가뜨릴 수 있는 가장 효과적인 노이즈 η를 찾는 최적화 수식이다.
그리고 본 논문에서는 수식 (8)과 같이 수식(7)을 실제로 계산하기 위해 시그마 기호를 활용하여 다양한 조건 c에 대해 모든 조건 c에 대한 손실을 합산하여 가장 효과적인 노이즈 η를 찾는 최적화 수식으로 바꿔서 제안했다.
위에서 제안한 최적화 문제를 해결하기 위해서 본 논문에서는 Iterative Class Transferable Disruption과 Joint Class Transferable Disruption이라는 두 가지의 새로운 방해 방법을 제안했다.

첫 번째 방법인 Iterative Class Transferable Disruption은 앞서 제안한 최적화 문제를 반복적인 방식으로 해결하는 방법이다.
I-FGSM처럼 여러 번의 반복(iteration)을 통해 적대적 노이즈 η를 점진적으로 업데이트하는 방식이다. 각 반복 단계마다 손실 함수 L(G(x + η), r)의 그레이디언트를 계산하고, 이를 이용하여 η를 조금씩 조정하면서 최적의 η를 찾아낼 수 있다. 이를 통해 다양한 클래스 조건 c에 대해 효과적인 노이즈를 생성할 수 있고, 여러 조건에 대해 전이 가능한 방해 효과를 얻을 수 있다.
두 번째 방법인 Joint Class Transferable Disruption은 첫 번째 방법과는 다르게 모든 조건 c에 대해 동시에 최적화하는 방법이다. 점진적으로 반복하며 모든 조건에 대한 손실을 한꺼번에 고려하여 노이즈 η를 업데이트한다. 이를 위해 각 조건 c에 대한 손실을 합산한 뒤 그 총합을 기반으로 η를 조정한다.
3.3. GAN 적대적 훈련
다음으로는 이러한 공격을 방어하기 위한 Defense 기법 중 하나인 적대적 훈련을 GAN에 적용하는 내용에 관한 설명이다.
적대적 훈련은 일반적으로 분류 모델에 대한 적대적 공격을 막는 방법으로, 트레이닝 데이터셋에 적대적 예제를 포함시켜 함께 훈련을 진행하면 적대적 공격에 강건(robust)한 모델을 구축할 수 있다.
본 논문에서는 이를 활용하여 생성형 적대적 신경망에 적대적 훈련을 적용한 첫 번째 적용을 제안한다.
이를 위해선 GAN의 학습 과정과 각각의 손실 함수에 대해 먼저 알아야 한다.
먼저 GAN의 학습과정은 다음과 같다.

Generative Adversarial Network(GAN)는 위와 같이 두 가지 신경망인 생성자(Generator, G)와 판별자(Discriminator, D)가 서로 경쟁적으로 학습하는 구조를 갖고 있다.
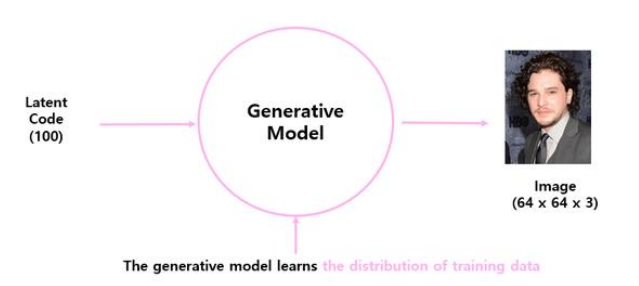
생성자 G는 랜덤한 노이즈 벡터 z를 입력으로 받아 가짜 이미지 G(x)를 생성한다. 생성자의 목표는 판별자가 진짜라고 판단하도록 최대한 진짜와 유사한 이미지를 생성하는 것이다.

판별자 D는 진짜 이미지와 가짜 이미지를 입력으로 받아, 해당 이미지가 진짜(real)인지 가짜(fake)인지 구분하는 역할을 한다. 즉 판별자 D는 진짜 이미지를 1에 가깝게, 가짜 이미지를 0에 가깝게 분류하는 것이 목표이다.
이제 GAN 모델의 손실함수를 살펴보자.

GAN의 전체적인 목적은 위와 같은 손실함수로 표현된다. 앞 부분의 E[log(D(x))]는 진짜 데이터 x에 대해 판별자 D가 진짜로 판별하도록 학습하는 부분이고 뒷 부분의 E[log(1 - D(G(z)))]는 가짜 데이터 G(z)에 대해 판별자 D가 가짜로 판별하도록 학습하는 항목이다. 이 과정에서 판별자 D는 진짜 이미지를 진짜로, 가짜 이미지를 가짜로 정확하게 구분할 수 있도록 최적화 되고, 동시에 생성자 G는 판별자가 가짜 이미지를 진짜라고 오분류하도록 최적화된다.
기댓값으로 표현한 수식을 수학적으로 표현하여 판별자와 생성자의 손실 함수를 나타내면 아래와 같다.


이제 본격적으로 본 논문에서 제안하는 GAN을 위한 적대적 훈련에 대해 살펴보자.

본 논문에서는 조건부 이미지 변환 GAN에서 수식 (11)과 같은 손실 함수를 사용한다고 하였다. 이때, D는 판별자를 나타낸다.
먼저, E[logD(x)]는 진짜 이미지 x에 대해서 판별자 D가 진짜로 인식하도록 하는 손실 항목이다.
다음으로 E[log(1 - D(G(x, c)))]는 생성자 G가 조건 c를 기반으로 만든 가짜 이미지 G(x, c)에 대해, 판별자가 가짜로 인식하도록 하는 손실 항목이다.
본 논문에서는 생성자가 적대적 예제에 대한 저항성을 갖도록 하기 위해 수식 (12)와 같이 기존의 판별자 손실 함수를 변형하여 생성자 손실 함수 부분에 노이즈 η를 포함하여 함께 학습하도록 진행하였다.
또한, 본 논문에서는 아래와 같이 생성자와 판별자 손실 각각에 대해서 노이즈를 삽입하여 각각 적대적 훈련을 진행하는 방법도 수식 (13)과 같이 제안하였다.

위 수식은, 진짜 이미지 x에 대해서도 노이즈 η1을 추가하여 판별자 D가 해당 이미지를 진짜로 판별하도록 훈련하도록 하며, 생성자 G에 대해서는 조건 c에 따라 노이즈 η2가 추가된 입력 이미지 x를 기반으로 생성한 가짜 이미지에 또 다른 노이즈인 η3을 추가하여 최종적으로 G(x + η2, c) + η3을 판별자 D에 입력하여 이렇게 여러 노이즈가 추가된 가짜 이미지를 가짜로 인식하도록 훈련을 진행한다.
정리하면, 수식 (13)의 앞 부분은 노이즈 η를 가진 진짜 이미지를 판별자가 진짜로 인식하도록 하는 부분이고, 뒷 부분은 η를 가진 가짜 이미지를 판별자가 가짜로 인식하도록 훈련하는 부분이다. 이와 같은 과정을 통해 생성자 G와 판별자 D는 적대적 공격에 더욱 robust 해질 수 있다.
---
이후 파트부터 추후 작성
3.4. 블러 방어의 확산 스펙트럼 회피
4. Experiment
실험 모델 아키텍처 및 데이터셋 설명
4.1. 이미지 변환 방해
4.2. 클래스 전이 가능한 적대적 방해
4.3. GAN 모델의 적대적 훈련 및 기타 방어
4.4. 블러 방어의 확산 스펙트럼 회피
5. Conclusion
'Paper' 카테고리의 다른 글
| [Paper Review] Denoising Diffusion Probabilistic Models (2) | 2024.12.02 |
|---|---|
| [Paper Review] Explaining and Harnessing Adversarial Examples(FGSM) (2) | 2024.08.30 |
| Face Identification, Recognition, Verification 오픈소스 정리 (0) | 2023.08.24 |
| [Paper] Face Recognition 관련 논문 정리 (0) | 2023.08.24 |